漢字ROM
漢字をLCD表示させたいので、漢字フォントをROM化(EEPROMに記憶)しました。既に、多くの方が行っているので
それらの内容を参考・流用させて頂いて何とか、1MBit(128kバイト)のEEPROMに必要な全角12x12フォントと半角
5×8フォントおよび、半角→全角変換テーブルを収めました。
ROM割当結果
①全角 12x12 6985文字 125,730バイト
②〃 空白
234文字
4,212バイト
(内384バイトを半角→全角変換テーブルとして使用)
③半角 5x8 158文字 790バイト
④〃 空白
34文字
170バイト
⑤未使用
170バイト
計 131,072バイト(128kバイト)
ROM化の手順
全角文字コード体系(ShiftJIS)
上位 81h~9Fh、E0h~EAh
下位 40h~FCh、(除く7Fh)
半角文字コード体系
20h-7Fh,A1h-DFh
全角文字コードの上位と半角文字コードは、重ならないように考慮されています。
全角文字を体系にそって、単純に1文字24バイトとした場合の必要な領域は
上位42 x 下位189 x24 =約186kバイト
となり、1Mbitにはとても収まらいので、まず1文字の容量を見なおした。
1文字は、処理を簡単にするため、12x12ドットの上側8ドットを1バイトとして12バイト、
下側4ドットも空白4ドットを0で埋め8ビットとして12バイト、計一文字24バイトと考えました。
しかし、下側上位4ビット(黄色の部分)が常に0であり、48ビット(6バイト)分が無駄になるため、
下側は1バイトで2行分のデータにする。
下の例の下側データ(HEX)
0C 03 00 09 09 05 03 01 03 05 09
00(圧縮前)
⇓
C3 09 95 31 35 90(圧縮後)

これで、一文字当たりの容量を24バイトから18バイトに圧縮する。
必要な容量 上位42 x 下位189 x18 =約140kバイト
まだ、必要容量が大きいので文字コードの隙間の部分を削ることを考えた。
文字コードから、ROMアドレス変換を極力単純化するため、文字ごとにテーブル
を作らず、連続した空白を削って文字コードから関数的に変換する方式とする。
空白部分 84BFh-86FCh 7,920バイト
8791h-87FCh 1,728バイト
8840h-889Eh 1,710バイト
EAA5h-EAFCh
1,584バイト
計 12,942バイト
上位42 x 下位189 x 18 - 12,942
=129,942(127kバイト)
これで、半角領域980バイトを足しても、ぎりぎり1Mbit(128kバイト)に収まる。
129,942+960=130,902(127.9kバイト)
以上の内容をメモリマップにすると、以下のとおり。
メモリマップ
|
文字コード
(ShiftJIS) |
文字数 |
バイト数 |
ROMアドレス |
|
8140h-84BEh |
694 |
12,492 |
00000h-030CBh |
|
8740h-8790h |
93 |
1,674 |
030CCh-03755h |
|
889fh-88FCh |
94 |
1,692 |
03756h-03DF1h |
|
8940h-9FFCh |
4,347 |
78,246 |
03DF2h-16F97h |
|
E040h-EAA4h |
1,991 |
35,838 |
16F98h-1FB95h |
|
スペース(一寸開けた) |
10 |
1FB96h-1FB9Fh |
|
半角20h-DFh |
192 |
960 |
1FBA0h-1FF5Fh |
|
余 白 |
160 |
1FF60h-20000h |
文字コードからROMアドレスへの変換式(H:上位、L:下位コード)
8140h-84BEh ((H-81h)*189+L-40h)*18+00000h
8740h-8790h (L-40h)*18+030CCh
889Fh-88FCh (L-9Fh)*18+03756h
8940h-9FFCh ((H-89h)*189+L-40h)*18+03DF2h
E040h-EAA4h ((H-E0h)*189+L-40h)*18+16F98h
半角 20h-DFh
(L-20h)*5+1FBA0h
これで、OKと思いましたが半角文字をLCD表示させるとき、高さや幅を考えると全角に変換した方がいい時も
あるので、半角から全角に変換するテーブルがほしいので、それも追加したいと考えました。
2バイトで192文字分なので384バイト必要ですが、余白だけでは足らないので全角領域で文字が割り当てられ
てない連続した領域で確保できる場所を探し、そこにコードを埋めました。
ROMアドレス 25D4h-0x2753h 無文字部を含め192文字、384バイト
(半角コード - 20h)x2 + 25D4h 2バイト読込 ⇒ 該当するROMアドレスから全角文字フォント読出
以上の内容のバイナリデータ font00.dat
データのEEPROMへ書き込み方法 の一部修正 ソース VBAのマクロ部
漢字ROMを用いたLCD表示
回路図
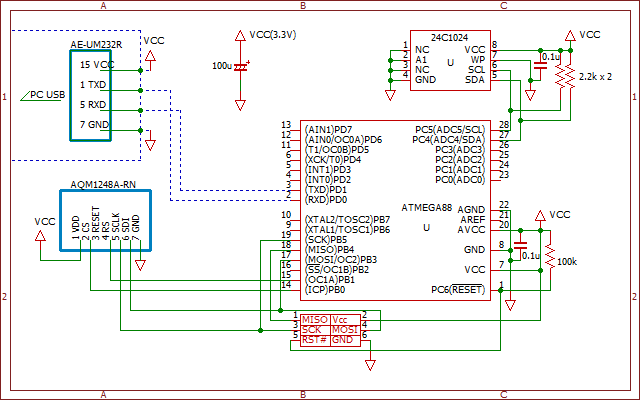
LCD AQM1248A-RN
48×128ドット
ソース PCからテキスト送信(Tera
Term等)し、最大10文字(+CR+LF)、3行分表示
全角一行 12ドット、間隔1ドット、10文字(10文字目は11ドット表示)
縦方向は、2ページ分(16ドット)で1文字表示(4ビットの0は行間)
全角文字は文字コード97b2h以降はROMアドレス17ビット(P0)を1
半角は全角に変換させ表示(17ビットは常に0)
I2Cは、SDA・SCLピンを使用しているが内蔵処理を使わず、手動処理で実現
表示例

参考サイト
電子工作の実験室(後閑さん) 漢字表示グラフィック液晶表示ライブラリ
放課後の電子工作(ちあきさん) Timpy
Rev4.0 技術情報
フォントデータ(津邑さん) CJKOS Japanese
Fonts