PyQtでお手軽GUI開発♪―――は可能だったか? 第11回 Cython vs Numba 編
前回、残念なことにPythonは太古のDelphi6に17倍ものスコアでぶっちぎられてしまいました。もしそれで終わりならばPyQtというものの使い所も限られてきてしまいます。しかしそもそもPyQtに手を出したのは最初からある程度の勝算があったからでした。
なぜなら公式FAQに以下のような一文があることに気づいていたからです。
pure Python にできる限界に達したなら、更に進むためのツールがあります。例えば、 Cython は、Python コードのわずかに変形した版を C 拡張にコンパイルし(中略)コードの解釈を大幅に速くします。
というわけで今回はそのCython(しーそん?)と、それの調査過程で見つけたNumba(ぬんば)というものの実力を試してみることにします。
Pythonが遅い理由
そもそもPythonが遅いということは最初から分かっていたことです。
まずPythonはインタープリタです。これはソースを毎回行単位に解釈して実行する仕組みなので、コンパイラより遅くなるのは仕方ありません(その代わりに対話的実行ができるなどの別の大きなメリットがあるわけですが)
しかしそれ以上に問題になるのが、Pythonが型無し言語(あるいは動的型付け言語)であることです。
PascalやCなどのほとんどの言語では、変数や関数はあらかじめ「型」と共に宣言してからでないと使えないようになっています。しかしPythonではいつでもどこでも、ユーザーは変数の型をまったく気にすることなく使用を始めることができます。
しかしそういう利便性があれば、反面パフォーマンスが犠牲になってしまうのは致し方ありません。
なぜならPython上でいくら型がなくてもPythonを実装しているのは結局C言語などの型付き言語です。従ってその内部では結局、状況に応じて自動的に型を判断して、必要ならば型変換して処理を行うわけです。そのため変数や値は、単なる数値であっても複雑な内部構造を持つオブジェクトになっています。
また変数にどんな型のデータを入れてもいいということは、さっきまでこの型だったからといって、今回もそうだとは限らないということを意味しています。すなわちその変数が使われるたびに―――代入にしても比較にしても、あらゆる処理の前に毎回型のチェックを行わなければなりません。
こういうことをしなければならないとなると、パフォーマンスに悪影響があるのは不可避です。
しかし、反面それは変数の型が定義できたならそんなところを大幅に効率化できるということも意味します。またさらにインタープリタの処理ではなく、あらかじめコンパイルできればもっとパフォーマンスは上がるでしょう。
CythonとはPythonをちょっと拡張してC言語相当の型情報を定義できるようにして、それをCのソースに変換するツールです。
この説明の通りならば使うにはそれなりの手間がかかりそうです。しかし当コラムのモットーはお手軽開発なので、できればもう少し楽な方法はないかといろいろいろいろ情報を漁っていたら、今度はNumbaというのを見つけました。
これもPythonの高速化モジュールなのですが―――なんでもデコレータ一発で使える⁉ って、にわかには信じがたいのですが……
そこでともかく両者を入れて試してみようとしたら、前述の騒ぎになったのでした。
Numbaの挑戦
そんなわけで何とかAnacondaが入って環境が整ったので、実際に試してみることにします。
もちろん最初は簡単そうなNumbaの方からです。
これに関してはあまり日本語のドキュメントがないんですが、リンク先をGoogle翻訳するだけで結構分かるし、何よりも基本的な使い方が……
from numba import jit #Numbaからjitという関数をインポート @jit #それで高速化したい関数をデコレート def calc2(a0, b0, cmax): 以下略
―――これで終わりなのです。
jitというのは“Just In Time”の略で、要するにプログラム実行中に動的に関数をコンパイルしてくれるデコレータなんだそうですが―――半信半疑で自分で作ったマンデルブロ集合の計算関数に適用してみると……
よく分からないエラーが出て、Numbaの中で死んでます。
やっぱり世の中そう上手くはいかないようです。
もちろんこの時点では何が何だかまだよく分かっていません。
そこでともかくこんな場合は可能な限りシンプルなものから始めてみるのが鉄則と、関数を細分化してみます。この頃はまだ色々と試行錯誤の真っ最中だったので、マンデルブロ関数の計算部分も関数化されておらず、かなりぐちゃぐちゃになっていました。Qtでの描画もその頃は関数の中でやっています。
そこで計算部分だけを関数化して再度やってみると……
しかしマンデルブロ集合の計算関数などという四則演算しかしてないようなものが動かないのは、あまりにも変でしょう。そこでふっと気になったのが、その頃はCMAXとかのパラメータをクラスのメンバ変数にしていたことでした。関数化というのも例えば以下のような感じで、関数内のサブ関数で定義していました。
def mandel_p(self, a, b, pw): @jit def calc2(a0, b0): x0, y0 = a0, b0 xx0, yy0 = a0*a0, b0*b0 for n in range(self.cmax): #cmaxはクラスのメンバ変数 以下略
もしかしてこれが何かまずいのか? と思って、cmaxをきっちり関数のパラメータとして与えてやることにしてみたら……
描画時間: 330.3 ms
- もちろん前回と同じパラメータで実行しています。
あれ? ちょっとなんですか? たしかに画面の描画はされてるし? 見間違いでしょうか?
そこでもう一度やってみると……
描画時間: 133.9 ms
………………
…………
……
見間違いではありません。
2回目以降からはDelphi6の350msを2倍以上ぶっちぎってます‼ 最初の1回はコンパイルが入るんでちょっと遅いですが、それでもDelphiより速いじゃないですか⁉
結局最初に動かなかったのは以下のような理由のようです。Numbaのドキュメンテーションのトラブルシューティングに1.9.2. My code doesn’t compileというのがあるのですが、それをおおざっぱに訳すと……
1.9.2 私のコードはコンパイルされません
Numbaがコードをコンパイルできず、代わりにエラーが発生する理由は、サポートされていないPythonの機能に依存していること。もう1つの理由は、コードの一部で型の推論が失敗したことです。
四則演算しかしていないプログラムがサポート外のわけがないので、理由はどうやら後者のようです。多分Numbaは唐突に出てきたself.cmaxを見てパニクってしまったのでした。
―――さて、それはそうと今の例はcalc2のアルゴリズムに対しての適用でした。そこで他のアルゴリズムに対してどのようなことになるかを見てみましょう。
すると……
関数 Python Numba 倍率 コメント ------------------------------------------------------------------------------- calc0 23,352 136 171.3 素朴なバージョン calc1 7,472 137 54.6 2乗をかけ算に、平方根の使用をやめる calc2 6,634 129 51.5 2乗の計算を1回にする calc3 5,919 141 42.0 複素数を利用する ------------------------------------------------------------------------------- ※時間の単位はms
なんだか一番素朴なcalc0でも同じくらいに速くなってるんですが……これだとPythonのみのときに比べて170倍以上のスコアをたたき出しています。Numbaというのはツボにはまると凄まじい破壊力を示すようです。
しかし―――何かこれっていきなりラスボスをぶっ倒しちゃってるんじゃないでしょうか?
正直最初はDelphiのネイティブコードコンパイラにNumbaとかCythonがどの程度肉薄できるか? という勝負になると思っていました。だから「Numbaがやられたようだな。ふふ、奴は四天王の中では最弱……」とかいったネタをかますべく準備もしてたんですが……
むしろ最初の自爆が「ふっ、悪いな、ちょっと力の使い方に慣れてなかったぜ」みたいなことになってしまっててw
それはそうとNumbaがこれならCythonはもっとできる子なのでしょうか⁈
Cythonの力
何だかもう十分なスピードは出てるような気はしますが元はといえばこちらを調べていたのだし、せっかくなのでCythonのほうも試しておきましょう。
Cythonを使うには以下の手順を踏むことになります。
- まずPythonでちゃんと動くプログラムを作っておきます。
- 高速化したい関数をモジュール化して拡張子をcpxにします。こうした時点でもうPythonからは読めなくなるので、元のプログラムがPythonレベルでちゃんと動いているということは非常に重要です。
- Pythonから呼び出される関数は今までどおり def を使いますが、モジュール内でのみ使用される関数は cdef というキーワードで定義します(そうすることでややパフォーマンスが上がります)
- 以下のように変数や関数引数に型指定をします(詳細はこちらを参照)
cdef calc2(double a0, double b0, int cmax): #関数宣言をcdefにしてパラメータを型指定する """2乗を2回計算しているのを1回にする""" cdef: #内部で使用する変数も同じcdefで型宣言する int n double x0, y0, x1, y1, xx0, yy0 x0, y0 = a0, b0 xx0, yy0 = a0*a0, b0*b0 for n in range(cmax): x1 = xx0 - yy0 + a0 y1 = 2*x0*y0 + b0 xx0, yy0 = x1*x1, y1*y1 if xx0 + yy0 > 4: break x0 , y0 = x1, y1 return n cdef mandel(self, double a, double b, double pw, int iw, int ih, int cmax, calc, app): #こちらも引数の型定義 """マンデルブロ集合を描画する(Pythonベース)""" cdef: #変数の型定義 int i, j, n double a0, b0 for j in range(ih): b0 = b + pw*(ih - j) for i in range(iw): a0 = a + pw*i n = calc(a0, b0, cmax) self.mandeldata[j][i] = n def mandel_c(self, double a, double b, double pw, int iw, int ih, int cmax, calc, app): #Pythonから呼び出される関数の定義 mandel(self, a, b, pw, iw, ih, cmax, calc2, app)
- できあがったソース(ここではMyModule.pyxとします)をコンパイルします。そのためには以下のようなスクリプトを作り(ここではsetup.pyという名前にします)
from distutils.core import setup from distutils.extension import Extension from Cython.Distutils import build_ext setup( cmdclass = {'build_ext': build_ext}, ext_modules = [Extension('MyModule', ['MyModule.pyx'])] )
- コマンドラインで以下のようにスクリプトを実行します。
python setup.py build_ext --inplace
- ここ、わりと面倒なんでこんなもんを作ってみたりもしました。
- そうするとまずPythonソースからCのソースが出力されて、それがコンパイルされると例えば MyModule.cp35-win_amd64.pyd といった名のついたPythonのバイナリモジュールができあがります。
- それができればMyModuleをPythonにimportして使えるようになります。
このようにわりと手間はかかりますが、最初のPythonの時点でちゃんとデバッグできていればあとは機械的な変換作業です。
- cpxレベルでいろいろ修正を始めると、何かあってもPythonのPDBデバッガでは追えません。Cython用のデバッガもあるようですが、何かすごく面倒そうです。
- それにしても元が5KBのpyファイルから出力されるCのファイルサイズが249kBとか、何やってるんでしょうねえ……
ともかくそうやって実行してみると……
描画時間: 93.3 ms
やりましたっ! 100msを切りましたっ!
しかしこのぐらいの実行速度になると、結構ばらつきが激しくなります。そこで次節でもうちょっと詳しく調べてみましょう。
その前に一応、型指定無しでcalc2をコンパイルしたものを測定してみます。
すると……
描画時間: 4367.5 ms
Pythonのみで6秒ちょっとだったことを考えると、50%程度の効果です。ということは、Pythonが遅い理由はやはり大部分が型チェック関係ということのようです。
竜虎相まみえる
さて、こうなったら気になってしまうのがNumbaとCython、どちらが本当に速いのかということでしょう。
そこでまずループ500回の画像を10回実行して比較してみます。
Cython Numba Numba
calc2 calc0 calc2
------------------------------
1 84.3 124.8 105.5
2 98.6 130.4 122.3
3 102.5 132.9 127.1
4 102.8 134.6 127.2
5 104.8 135.6 127.7
6 104.8 135.9 128.1
7 111.6 139.3 128.5
8 112.1 141.5 128.8
9 114.4 142.2 133.4
10 121.0 148.5 143.2
------------------------------
平均 105.7 136.6 127.2
※時間の単位はms
こうやって見るとCythonの方がちょっとばかり速いようですが―――それでは今度はループを10000回にして比較してみます。
Cython Numba Numba Numba Delphi
calc2 calc0 calc2 calc3 calc2
------------------------------------------------------
1 1347.5 1514.7 1366.0 1505.7 6387.3
2 1350.4 1534.9 1373.7 1518.7 6406.3
3 1366.2 1536.6 1374.3 1536.2 6398.3
4 1368.3 1542.5 1377.3 1537.3 6419.1
5 1382.8 1542.5 1396.8 1547.2 6431.3
------------------------------------------------------
平均 1363.0 1534.2 1377.6 1529.0 6408.5
ループ500 68.2 76.7 68.9 76.5 320.4
※時間の単位はms
こうやってみるとCythonとNumbaの差はほぼないといっていいようです。
またここで出た結果を20で割った値が、ほぼループ500回を計算する時間に相当するわけですが、これと上の単に500回での実行時間の差が、おおむね関数が呼び出されるときのオーバーヘッドと考えていいでしょう。すなわちCythonの方がほんのちょっと呼び出しが速いかも(62500回呼び出されてこのくらいの差)というところです。
そこでついでにDelphiとも比較していますが、こうやって見るとNumbaやCythonを使えばDelphiの4~5倍のパフォーマンスが出るようです。
- ただし使っているDelphi6は15年以上前の、しかも32ビットコンパイラです。それに対してNumbaやCythonは最新の64ビットコンパイラでコンパイルされていることを考えると、むしろDelphi6がよく頑張っているということなのかもしれません。
ところでNumbaではcalc0のような素朴な関数までが爆速になっていました。そのあたりCythonの方はどうなのでしょうか?
そこでcalc0をCythonでコンパイルしてみたところ……
描画時間: 6576.9
なんと、Numbaに比べて滅茶苦茶遅いです!
確かに元の23秒とかに比べたら3.5倍と間違いなく効果は出ていますが―――そこでcalc0のsqrtを使っているところだけを、
if x1**2 + y1**2 > 4:
このように変更してみます(2乗をかけ算には変更しません)
すると……
描画時間: 2782.9 ms
それだけでかなりの効果がありました。
続いてcalc1をコンパイルしてみると……
描画時間: 96.7 ms
これだとほぼcalc2に匹敵する値が出てきました。
―――以上より言えることは、どうやらNumbaの方は型の推定以外にもいろいろと最適化をしているようなのに対して、Cythonは型指定だけをしていてそれ以外にはあまり手をつけないようです。
戦いの果てに
それにしても宿敵を倒すために手を組んで戦っていた仲間がいつの間にか雌雄を決してるみたいな展開になってますが、ここまでの結果を総合するとPythonのパフォーマンス改善に関しては、もうNumba大勝利というところでしょうか。
まずそもそもその使い勝手が全然違います。デコレータ一発で使えるNumbaに対して、Cythonはかなりの手間暇をかける必要があります。
そのうえNumbaではCythonのようにいちいち手で型指定する必要もありません。
これはむしろジャストインタイムコンパイラのメリットでしょうか。静的なソースをコンパイルするのと違って、Numbaは実際に呼び出されたタイミングでコンパイルを開始しますが、そのときには既に実引数がやってきているわけで、現物を見れば型も分かるからです。
- Numbaでもデコレータにさらにパラメータを与えて型指定することができるようですが、ちょっとやってみましたがどうも効果が分かりませんでした。NumbaにもCythonのように事前にコンパイルする機能があるようなのでそういう場合に役立つのかもしれません。
そのうえ基本性能も両者ほぼ変わらないといっていいでしょう。
Cythonの方がほんのわずかだけ関数呼び出しのオーバーヘッドが少ないようなので、ループ500回くらいだとCythonがちょっと速くなるようですが、ループを10000回にして比較してみるともうほとんど差は出ません。
Numbaのドキュメンテーションを見てみると、2.6 Supported Python featuresという項にはmathモジュールのいろんな関数が含まれています。すなわちNumbaの場合、x**2をx*xに変更するみたいなもっと突っ込んだ最適化がなされるようです。
というわけで……
Pythonプログラムの高速化が目的なら、まずはNumbaを使ってみるのがいい
―――というのがここでの結論となります。
ただしこれはCythonが使えないということではまったくありません。
そもそもCythonは高速化だけのツールではなく、CのライブラリをPythonで楽に扱えるようにするというもう一つの大きな目的を持っています。CythonのチュートリアルもCの関数を呼び出すというところから始まっていたりして、むしろこちらの方が主だといってもいいでしょう。
そして外部のライブラリを使うというのは、様々な実際的な目的を達成するために大抵はとても有効な方法です。そんな場合にCythonは間違いなく大きな威力を発揮しそうです。
いずれにしてもPythonのような遅い言語を高速化しようと思えば、プログラムをきちんと構造化して、正しくボトルネックを調べて、その場所にピンポイントで最適化を仕掛ける必要があります。
これがC言語などだと少々効率の悪いことを書いても何とかなってしまうところが、Pythonでは正しく対応しなければならないことを意味します。しかしそれに慣れていればCで書いてすら遅いような問題に直面した際にも間違いなく役に立つでしょうし、上手くいったときのじゃじゃ馬をならしたような達成感はまた格別ですw
それにしても―――正直Numbaには驚きました。
デコレータの説明のところで、ターゲットを MySpecialFunction に差し替えるとか書いてるのを見て、またこいつ馬鹿なことを言ってやがるなと思った方もいるかもしれませんが―――まさにこれがそういうことをやってます。
そういう意味じゃCythonががりがりと力業を繰り出しているのに比べて、Numbaはやり方がスマートというか、PythonのよくできたプロジェクトはSpyderだのAnacondaだのそういった毒々系の名前を持ってますが、NumbaはもちろんMambaのもじりで、ブラック・マンバは世界最強の毒蛇でユマ・サーマンだったりするし、Cythonというのはそういう意味ではあまりにも安直なネーミング―――いや、ここでCyponとしておけば、稼働中にOS書き換えちゃったりして名実ともに勝ててたかもしれないのに―――って、それってもしかしてNumbaがやってることじゃないですか? ってことはNumbaこそ真のしーぽんの名にふさわしいと?
- などと完全に錯乱してますがCythonは本当は「さいそん」と読むらしいです。
ともあれ―――ちなみにこれを書いている時点でのCythonのバージョンが0.25.2、Numbaが0.31.0と、どちらもまだ完全体ではないようです。現在Pythonが3.6になって、その売りの一つが関数や変数に型情報(アノテーション)がつけられるようになったことみたいですが、特にCythonの場合これに対応してくれたらまんまPythonコンパイラみたいになって便利なんじゃないかという気もしますがどうでしょう?
真の敵、現る!
さて、ともかく何にしてもこのくらいの速度が出てくれると、もうほとんどストレスなくマンデルブロ画像の描画ができてしまいます。前回のトップに出した画像でも1秒くらいで描けてしまうし、ループ回数を少なめにしたらリアルタイムアニメーションさえできそうです。
本当ならここで倒されたNumbaとCythonが「ふふ、その程度で勝ったと思うなよ、こちらはあと二回変身を残してるんだからな……」と言うようなネタも暖めてたんですが、何かもうすっかりやる気が失せてきました。
そこでしばらくはマンデルブロ世界の観光旅行としゃれ込むことにします。
マンデルブロ周遊の一つの楽しみ方が、ちびマンデルを探せ! です。マンデルブロ集合はフラクタル構造でも有名で、部分に全体のコピーがいくらでも含まれています。あの複雑な図形を拡大していくと例えば下図のように、そこここに元の集合そっくりの小さい奴が隠れているのです。
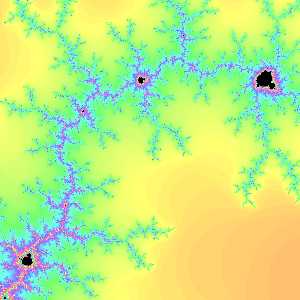
b=0.8731842041015625
pw=3.0517578125e-05
そんなちびマンデルを探していろいろ彷徨っていたときです。

b=-0.19884736127319602
pw=4.440892098500626e-16
どうやら何かがいそうな雰囲気です。

b=-0.19884736127314562
pw=1.1102230246251565e-16
ところが……
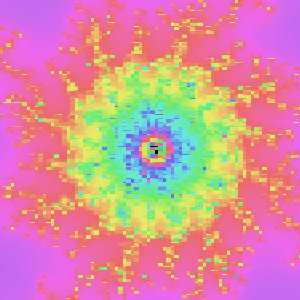
b=-0.19884736127313102
pw=1.3877787807814457e-17
いったいどういうことでしょう? どうして画面がモザイクに⁈
そこでpwの値をよく見てみると……
math.log2(4.440892098500626e-16) Out[2]: -51.0 math.log2(1.1102230246251565e-16) Out[3]: -53.0 math.log2(1.3877787807814457e-17) Out[4]: -56.0
なんだか1ピクセルのサイズが1/252よりも小さくなってますが―――ご存じの通り倍精度浮動小数点数doubleの仮数部は52ビットです。
通常の計算の場合、有効桁数がこの程度あれば困ることはまずありません。しかしマンデルブロ集合の画像を描く場合にはこういう小さい値の差が重要なのですが、1ピクセルのサイズが精度以下になってしまうと値が丸められてしまって、その結果モザイクになってしまうわけです。
1/252というのはdoubleでの解像度の限界だったのです。
うぬ。敵も然る者。こんな方面から攻めてくるとは―――と、しばらく呆然としていましたが、なんか俄然やる気が出てきました! モザイクの先に何が見えるのか? その探求こそが男のロマン! ですよね?
それにもしこれがDelphiだったら正直頭を抱えていたと思いますが、今使ってるのはPythonなのです。公式のドキュメントに以下のような一文があります。
整数 (int)
無制限の範囲の数を表現しますが、利用可能な (仮想) メモリサイズの制限のみを受けます。
多倍長整数はPython2から使えていましたが、Python3からは整数型のデフォルトになっています。すなわちPythonでは特に何もしなくても、メモリの許す限りの大きな整数が扱えるということです。
それが何を意味するかというと―――浮動小数点がダメなら固定小数点を使えばいいじゃない ―――ということなのです。
―――ということなのです。
というわけで次回はモザイクを外せ!編になりますw
- なお、何か間違いなどがありましたらこちらの方にコメントしてください(質問等でも構いませんが、多分答える能力があまりないのではないかと思います)
◆おまけ:ファイル名を引数にとれるCythonのsetup.py
ところでCythonのコンパイルのためには個々のモジュールごとにsetup.pyを作らなければなりませんが、やっていたら相当に面倒だったので、ファイル名を引数にとってコンパイルできる奴を作ってみました。多分当初は難しいオプションなどは使わないと思うので、これでいいんじゃないかという気がします(いずれにしてもsys.argvを騙すとかいう邪悪なことをやってるんで使うのは自己責任でお願いしますw)
# -*- coding: utf-8 -*- """Cythonコンパイルスクリプト python setup.py build_ext --inplace と打つかわりに python cythonsetup.py filename でコンパイルできるようにする """ import sys from pathlib import Path from distutils.core import setup from distutils.extension import Extension from Cython.Distutils import build_ext filename = Path(sys.argv[1]) extname = filename.stem sys.argv = sys.argv[:1] sys.argv.append('build_ext') sys.argv.append('--inplace') setup( cmdclass = {'build_ext': build_ext}, ext_modules = [Extension(str(extname), [str(filename)])] )